En este tutorial vamos a aprender algunos conceptos básicos sobre cómo usar OpenRefine para tratar conjuntos de datos con el objetivo de transformarlos, corregir irregularidades y extraer información relevante de ellos. OpenRefine es uno de los programas más utilizados para trabajar con conjuntos de datos voluminosos y con problemas de normalización, aunque existen alternativas como Data Cleaner o Trifacta.
Para descargar e instalar OpenRefine acudiremos a su sitio web oficial, donde encontraremos versiones para Windows, Mac y Linux. En la misma página puedes encontrar instrucciones de instalación para tu sistema operativo.
Caso de uso
Una de las grandes ventajas de OpenRefine es que nos permite trabajar con conjuntos de datos muy voluminosos y realizar transformaciones potentes de manera sencilla. Para nuestro ejemplo vamos a partir de todos los datos del Boletín Oficial de la Junta de Andalucía disponibles a 6/8/2017. Todos los datos disponibles a esta fecha se han incorporado al siguiente fichero CSV de origen.
A partir de este fichero tan voluminoso vamos a tratar de averiguar cuántas disposiciones normativas con fuerza de ley se han publicado cada año en el BOJA. En nuestro ordenamiento jurídico hay tres tipos de normas con fuerza de ley:
- Ley
- Decreto-Ley
- Decreto legislativo
Por tanto, para resolver nuestra pregunta tendremos que atender a estos tres tipos de disposiciones.
Abrir los datos en OpenRefine
OpenRefine es una aplicación local que funciona sobre nuestro ordenador; sin embargo, se utiliza a través de un navegador web. Una vez que la ejecutemos, abriremos con nuestro navegador favorito la siguiente URL local:
Si todo funciona correctamente, veremos una pantalla como la siguiente:
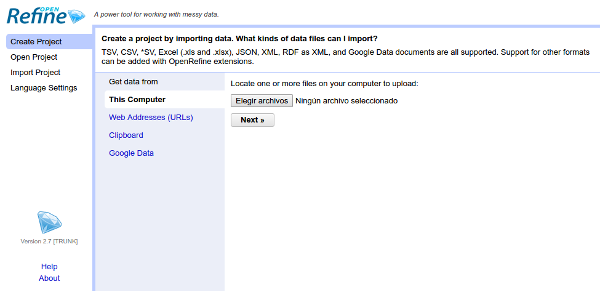
El siguiente paso es importar los datos, para lo cual haremos clic en "Elegir archivos" y buscaremos el fichero "boja.csv", que previamente habremos descargado en nuestro equipo. Aparecerá una pantalla de importación como la siguiente:
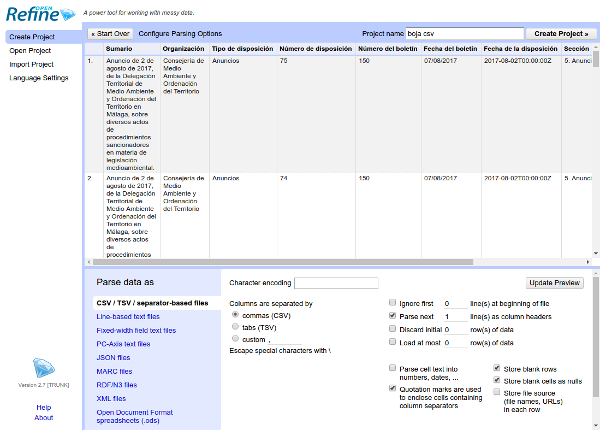
Tras comprobar que la vista previa es correcta, le pondremos un nombre al proyecto (p.ej. "boja csv") y haremos clic en el botón "Create Project". Comienza entonces el proceso de importación, que puede tardar unos pocos minutos.
Una vez importado, accederemos a la vista principal del proyecto:
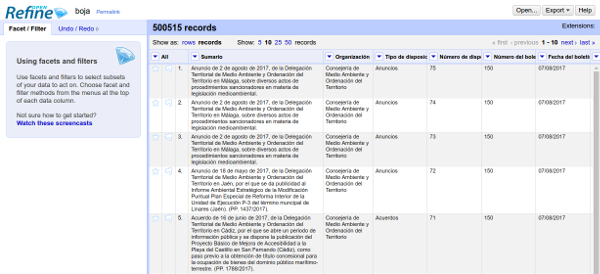
Trabajar con facetas en OpenRefine
La cuarta columna lleva como título "Tipo de disposición", por lo que parece una via prometedora para resolver la cuestión que nos habíamos planteado (cuántas de las disposiciones son leyes, decretos-ley o decretos legislativos). Para explorar los valores que toma esta columna crearemos una faceta de texto. Haz clic en el botón que aparece en el encabezado y escoge la opción "Facet" > "Text facet":
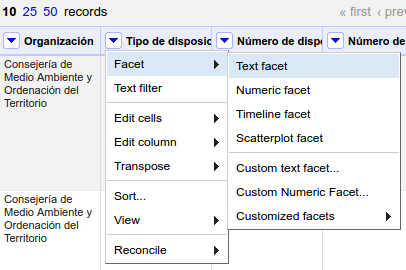
Aparecerá en el apartado "Facet/Filter" una nueva faceta con los distintos valores que toman los registros en la columna "Tipo de disposición":
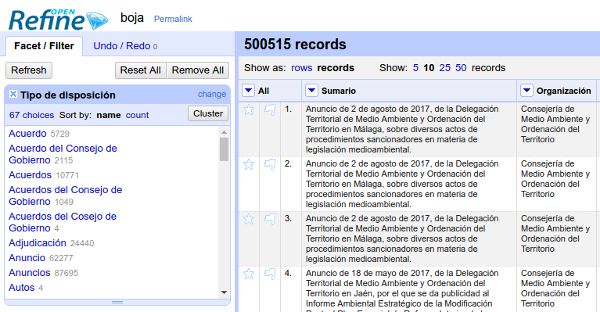
Como vemos, los valores de la columna no están normalizados. Por ejemplo, en 62.227 ocasiones se utiliza el texto "Anuncio" y en 87.695 ocasiones "Anuncios". Hay una manera muy sencilla de corregir esta irregularidad: sitúa el ratón sobre "Anuncio" y elige la opción "Edit". En la ventana emergente, escribe "Anuncios" y pulsa "Apply":

Ya hemos corregido la irregularidad en el caso de los anuncios. Podríamos seguir corrigiendo todos los valores de la faceta con este procedimiento, pero sería muy laborioso. Afortunadamente, OpenRefine tiene una herramienta para ayudarnos con esta cuestión.
Haz clic en el botón "Cluster" situado sobre los botones de la faceta; aparecerá una ventana con distintas sugerencias de valores para la faceta "Tipo de disposición" que detecta que son similares, junto con una sugerencia de etiqueta para el nuevo grupo. Puedes probar con distintos métodos para calcular la similitud y umbrales de tolerancia. Por ejemplo, estas son las sugerencias que se obtienen con el método "Levenshtein":
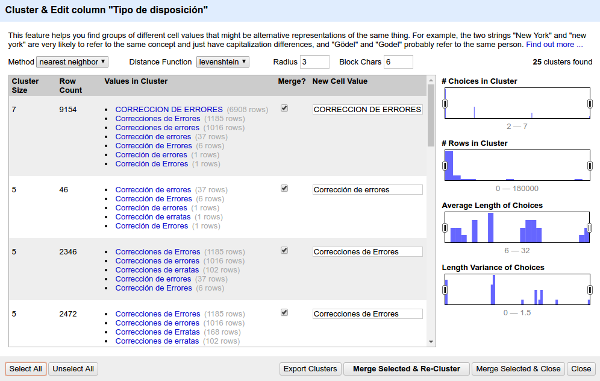
En esta pantalla puedes marcar las sugerencias que estimes apropiadas y asignarles una etiqueta; cuando termines, pulsa la opción "Merge Selected & Close". Con este método podemos normalizar más fácilmente los distintos valores de la faceta "Tipo de disposición".
Una vez que lo tenemos normalizado, podremos hacer clic en los distintos valores que nos interesen y el listado de registros se irá actualizando en consecuencia, como muestra la siguiente imagen:
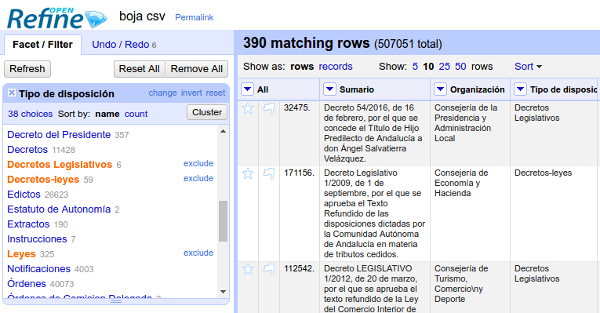
Como podemos ver en la imagen, la asignación del "Tipo de disposición" no es correcta en dos de las filas (el primero es un decreto, no un decreto legislativo, y el segundo es un decreto legislativo, no un decreto-ley). Como vemos, este camino no nos va a dar un resultado fiable; es mejor cambiar de estrategia. Elimina la faceta "Tipo de disposición" haciendo clic en el botón con forma de "X".
Usar expresiones en OpenRefine
Existe un mecanismo más poderoso para transformar los datos dentro de OpenRefine; utilizar expresiones. Para resolver la cuestión que nos planteábamos al comienzo de este tutorial vamos a usarlas con dos objetivos: obtener el año de publicación de cada disposición y averiguar cuáles son leyes, decretos-ley o decretos legislativos.
Obtener el año de publicación
En la columna "Fecha del boletín" aparece la fecha de publicación en formato DD/MM/AAAA, y queremos extraer el valor de año únicamente. Para ello, vamos a agregar una nueva columna a partir de la actual, haciendo clic en el botón que aparece en el encabezado de la columna:
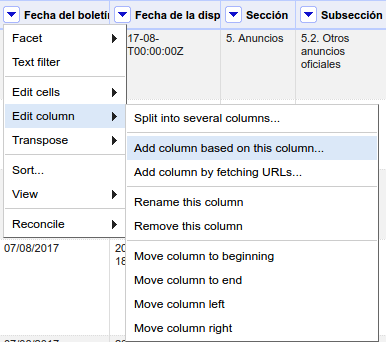
A continuación nos aparecerá una ventana en la que podremos introducir el nombre de la columna nueva y una expresión para transformar el valor de la celda. Introduce como nombre de columna "Año" y como expresión lo siguiente:
split(value,"/")[2]
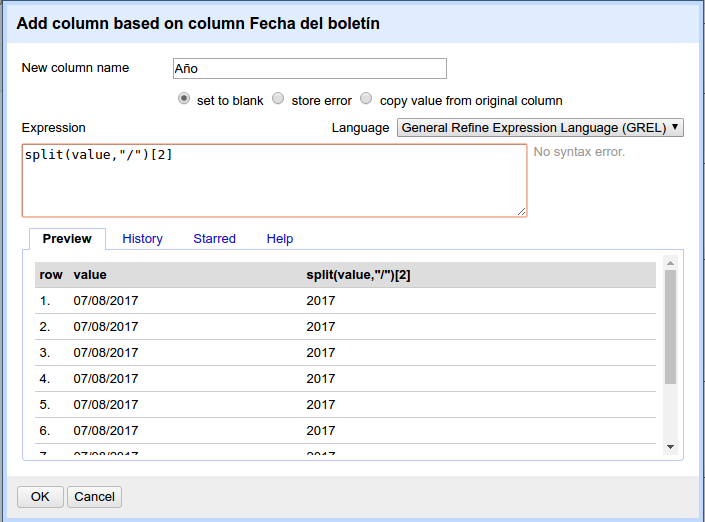
Las expresiones en OpenRefine se escriben habitualmente en un lenguaje llamado GREL. La explicación completa de GREL supera el alcance de este tutorial, por lo que nos limitaremos a explicar brevemente el significado de la expresión que hemos usado:
- La función "split" divide una cadena de texto con un separador que le indiquemos.
- La función recibe dos argumentos: value equivale al valor de la celda y "/" el carácter separador. De esta forma, el contenido de la celda se divide en una lista de tres elementos: DD, MM, y AAAA.
- El número [2] indica que se tome como valor el año (el tercero de estos elementos). A la hora de recorrer la lista, la cuenta comienza en el 0, por eso para mostrar el año debemos introducir el valor [2].
Al pulsar "OK" se crea la columna "Año" con el valor correspondiente.
Obtener el tipo de disposición
Para obtener el tipo de disposición, vamos a analizar el texto que aparece en la columna "Sumario" para buscar las disposiciones que comienzan por "Ley", "Decreto-ley" (y su variante "Decreto Ley") o "Decreto legislativo". En estos casos, queremos almacenar el tipo de disposición en una columna. Para ello, vamos a incorporar una columna a partir de "Sumario" con el mismo procedimiento que vimos en el caso anterior ("Edit column" > "Add column based on this column").
La expresión en este caso es más larga:
if(value.toLowercase().startsWith("ley"),"Ley",if(value.toLowercase().startsWith("decreto ley"),"Decreto-Ley",if(value.toLowercase().startsWith("decreto-ley"),"Decreto-Ley",if(value.toLowercase().startsWith("decreto legislativo"),"Decreto Legislativo","Sin valor de ley"))))
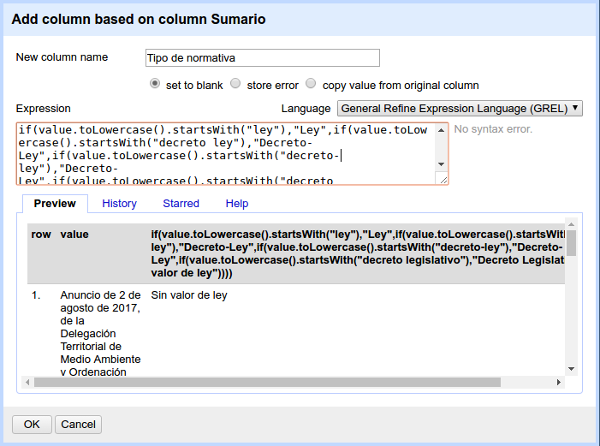
La expresión se compone de una serie de condiciones encadenadas entre sí, introducidas por la función if, que recibe tres argumentos:
- El primer argumento recoge la condición a comprobar, por ejemplo value.toLowercase().startsWith("ley")
- toLowercase convierte el valor de la celda a minúsculas, para que no nos afecte el uso irregular de mayúsculas (p.ej. "LEY" y "Ley").
- startsWith indica que el valor, una vez convertido a minúscula, debe comenzar por la cadena introducida (en este caso, "ley").
- El segundo argumento recoge el valor que debe asumir la celda si se cumple la condición especificada (p.ej. que tome el valor "Ley").
- El tercer argumento indica qué hacer si la condición no se cumple (p.ej. ejecutar otra función if, introducir un valor distinto...).
Al pulsar "Ok", OpenRefine crea la columna solicitada.
Filtrar y exportar los datos
Ha llegado el momento de filtrar los datos que nos interesan y exportarlos a un fichero con el que podamos seguir trabajando. Para ello, el primer paso es crear una faceta de texto a partir de la columna "Tipo de normativa". Como explicamos anteriormente, haz clic en el botón que aparece en el encabezado de la columna y escoge la opción "Facet" > "Text facet".
Sobre la faceta de texto, marca las tres opciones que nos interesan ("Ley", "Decreto ley" y "Decreto legislativo"), situando el ratón sobre la categoría y pulsando la opción "include":
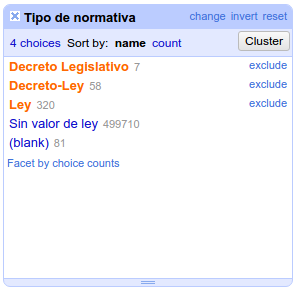
Si observamos los datos veremos que entre las disposiciones aparecen algunas leyes del estado, que se publican en el BOJA dentro de la sección 0. Como nos interesan solamente las que provienen de la Junta de Andalucía, vamos a hacer un filtro para excluirlas.
Crea una faceta de texto sobre la columna "Sección" (opción "Facet" > "Text facet"). Una vez creada, elige la sección 0; se mostrarán 7 normativas de ámbito estatal. Ahora pulsa en la opción "invert" situada justo encima del botón "cluster". como muestra el siguiente gráfico:
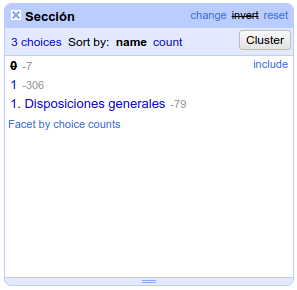
Ahora el listado muestra únicamente las disposiciones que no están en la sección 0, es decir, las autonómicas.
Ya tenemos el resultado que íbamos buscando; para exportar los datos, haremos clic en el botón "Export" situado en la parte superior del interfaz, y escogeremos el formato que más nos interese.
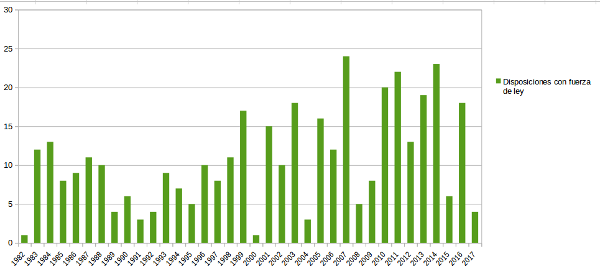
Por ejemplo, para avanzar en nuestro caso de uso podríamos escoger "ODF spreadsheet", abrir los datos con LibreOffice Calc y hacer una gráfica como la siguiente:
¿Te ha resultado interesante este tutorial? Puedes practicar lo que has aprendido con otros conjuntos de datos voluminosos, como los inmuebles propiedad de la Junta de Andalucía o las subvenciones concedidas.
¿Aún tienes dudas?
Si tienes cualquier duda o necesitas más información puedes contactar a través del siguiente formulario.